Failed to load content. Please try refreshing the page.
Understanding Load Balancers: The Backbone of Scalable, Reliable Backend Systems
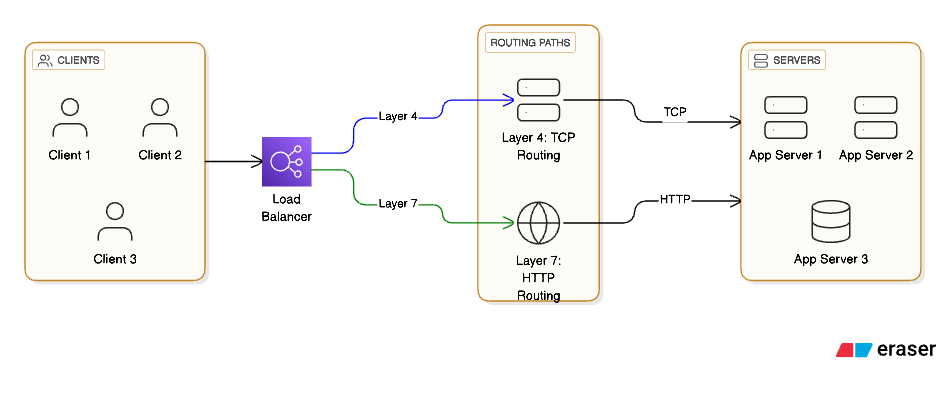
Learn how load balancers keep apps scalable, reliable, and fast with real‑world examples.
3 min read
Dec 28, 2025
20 views